Las 50 herramientas de seguridad más utilizadas
Según una encuesta hecha por Insecure.com a 1200 usuarios del NMAP en su lista de correo, las herramientas de
seguridad
preferidas e independientemente de la plataforma, son las siguientes:
Ordenadas empezando por la más popular, se agrupan utilidades como
scanners, sniffers y demás
programas de
seguridad.
Se incluye el enlace para descargarlas y una breve explicación sobre su
uso y/o utilidad teniendo en cuenta que hay algunas que no conocía.
*
Nessus (http://www.nessus.org): este programa es un scanner de
seguridad
empleado para hacer más de una auditoría en busca de vulnerabilidades.
Consta de dos partes, cliente y servidor (nessusd) con versiones para
Windonws, Java y Unix (la parte cliente) y sólo para Unix el servidor.
El servidor /daemon realiza los ataques mientras que el cliente
interactúa con el usuario a través de un interface gráfico. Pros:
desarrolla una completa exploración de todos los puertos y servicios y
presenta los puntos vulnerables que encuentra y sus posibles soluciones.
Contras: es un poco lento. Como comentario decir que es comparable al
Retina.
*
Netcat (http://www.atstake.com/research/tools/nc11nt.zip): esta sencilla utilidad para
Windows
y Unix sirve para escuchar y analizar las conexiones de red usando los
protocolos TCP o UDP. Se ha usado bastante para explotar el bug del
Isapi en los
servidores IIS (ref. Desbordamiento de búfer en el IIS del 21 de junio).
*
TCPDump (http://www.tcpdump.org): este sniffer
para Unix sirve para monitorizar todo el tráfico de una red, recolectar
toda la información posible y detectar así posibles
problemas
como ataques ping. Combinado con SNORT se convierte en una poderosa
herramienta solventando las carencias que ambos porgramas tienen por
separado. Es curioso porque podemos servirnos del propio TCPDump para
evadir IDSs de los que forma parte porque presenta una vulnerabilidad en
las capacidades de decodificación de DNS y puede entrar en un loop
infinito que nos permita saltarnos ese IDS (Sistema de Detección de
Intrusos).
*
Snort (http://www.snort.org): sniffer/logger,
Snort sirve para detectar intrusiones y ataques tipo búfer overflows,
CGI, SMB, scanneo de puertos, etc. Snort puede enviar alertas en tiempo
real, enviándolas directamente al archivo de Unix syslog o incluso a un
sistema
Windows
mediante SAMBA. Las versiones anteriores a la 1.8.1 presentan una
vulnerabilidad en la codificación Unicode que posibilita que un atacante
evada dicha detección.
*
Saint (http://www.wwdsi.com/saint): Security
Administrator’s Integrated Network Tool (SAINT) es una evolución del
conocido SATAN para plataformas Unix que sirve para evaluar toda la
seguridad de un sistema recibiendo incluso múltiples updates desde el CERT y CIAC.
*
Ethereal (http://ethereal.zing.org): este sniffer
de red para Unix tiene un entorno gráfico y soporta decodificación de
diversos protocolos pero presenta una vulnerabilidad de búfer overflow
(versiones anteriores a la 0.8.14).
*
Whisker (http://www.wiretrip.net/rfp/bins/whisker/whisker.zip): buen scanner de vulnerabilidades CGI.
*
ISS (http://www.iss.net): Internet Security Scanner es una herramienta comercial de análisis de vulnerabilidades para
Windows.
*
Abacus Portsentry (http://www.psionic.com/abacus/portsentry): demonio de Unix para detectar scanneos de puertos contra nuestros
sistemas capaz de bloquear al atacante mediante host.deny, filtrar las rutas o reglar el firewall.
*
DSniff (http://naughty.monkey.org/~dugsong/dsniff):
el nombre ya lo dice todo… este es un sniffer para buscar passwords y
el resto de información de una red incluyendo técnicas sofisticadas para
defender la “protección” de los switchers de red.
*
Tripwire (http://www.tripwire.com): esta es una utilidad para el análisis de red que sirve de gran ayuda a los adminsitradores de red.
*
Cybercop (http://www.pgp.com/products/cybercop-scanner/default.asp): este es un scanner de agujeros de
seguridad comercial que tiene versiones para
Windows y Unix y que es capaz de auditar
servidores, estaciones de
trabajo, hubs, routers, firewalls, etc.
*
Hping2 (http://www.hping.org): este programa
basado en el comando ping de Unix sirve para enviar paquetes ICMP,UDP y
TCP hechos a medida para mostrar las respuestas del obejtivo como
replicas ICMP echo (ping). Con hping conseguimos testar firewalls,
scannear puertos, etc. Nota: ICMP (Protocolo de Mensajes de Control
Internet).
*
SARA (http://www-arc.com/sara): Security Auditor’s Research Assistant es la tercera generación de herramientas para el análisis de
seguridad en plataformas Unix. La primera fue el SATAN (Security Administrator’s Tool for Analizing Networks) y la segunda el SAINT.
*
Sniffit (http://reptile.rug.ac.be/~coder/sniffit.html): otro sniffer de paquetes TCP/UDP e ICMP capaz de obtener información técnica muy detallada.
*
SATAN (http://www.fish.com/satan): hace falta decir algo sobre el más famoso scanneador de vulnerabilidades y analizador de red.
*
IPFilter (http://coombs.anu.edu.au/ipfilter): este
es un filtro de paquetes TCP/IP indicado para el uso con un firewall en
plataformas Unix. Puede trabajar como un módulo cargable del kernel o
incorporado en él directamente. Curiosamente, las versiones previas a la
3.4.17 presentan una vulnerabilidad que permite alcanzar puertos TCP y
UDP teóricamente protegidos.
*
IPtables/netfilter/ipchains/ipfwadm (http://netfilter.kernelnotes.org): herramientas para filtrar los paquetes IP bajo
Linux.
*
Firewalk (http://www.packetfactory.net/Projects/Firewalk):
programa para analizar las respuestas a los paquetes IP con la técnica
del Firewalking con una interface gráfica (opcional) para determinar los
filtros ACL de los gateways y los mapeos de red.
*
Strobe (http://www.insecure.org/nmap/index.html#other): scanneador de puertos de gran
velocidad.
*
L0pht Crack (http://www.l0pht.com/l0phtcrack): Esta es la conocida herramienta de auditoría para los passwords bajo
Windows. La última versión es la LC3.
*
John the Ripper (http://www.openwall.com/join): esta es una de esas utilidades que, yo por lo menos, recuerdo de toda la vida. Es uno de los
programas
que yo utilizaba cuando empecé a hacer mis primeros pinitos en esto del
hack y la verdad es que era el mejor crackeador de passswords para
Unix.
*
Hunt (http://www.cri.cz/kra/index.html#HUNT): este es un sniffer avanzado que funciona bajo redes ethernet pero que no conocía así que poca cosa puedo decir.
*
SSH (http://www.ssh.com/commerce/index.html):
Tenemos dos opciones usar el SSH que es de pago o utilizar en cambio el
OpenSSH que es una evolución del ssh para OpenBSD. SSH o Secure Shell,
es un protocolo o programa que se sirve de dicho protocolo, que permite
una conexión cifrada y protegida entre dos máquinas (normalmente cliente
servidor) que sirve para substituir al telnet y poder acceder y
administrar
sistemas remotos de manera segura.
*
TCP Wrappers (ftp://ftp.porcupine.org/pub/security/index.html): pequeños
programas
que permiten una conexión controlada, restringiendo determinados
servicios del sistema. Se pueden monitorizar y filtrar las peticiones de
entrada de servicios como Systar, Finger, FTP, Telnet, Rlogin, RSH,
TFTP, etc. El wrapper reporta el nombre del cliente y del servicio que
ha solicitado pero no intercambia información con el cliente o el
servidor de la aplicación/servicio solicitado porque lo que hace es
comprobar si el cliente tiene permiso para utilizar el servicio que está
pidiendo y si no es así, corta la conexión.
*
NTOP (http://www.ntop.org): utilidad para Unix que
permite visualizar en tiempo real los usuarios y aplicaciones que están
consumiendo recursos de red en un instante concreto. Tiene como un
microservidor web que permite que cualquier usuario que sepa la clave
pueda ver la salida NTOP de forma remota con cualquier navegador.
*
Traceroute/ping/telnet (http://www.linux.com): herramientas de Unix y
Windows (en este
sistema operativo el comando treceroute se denomina tracert).
*
NAT (http://www.tux.org/pub/security/secnet/tools/nat10): NetBios Auditing Tool sirve para explorar los recursos compartidos a través del protocolo NetBios en un sistema
windows.
*
Scanlogd (http://www.openwall.com/scanlogd): programita que detecta los scanneos de puertos que alguien pueda hacer contra tu sistema.
*
Sam Spade (http://www.samspade.org): herramientas online para investigar una dirección IP y encontrar spammers.
*
NFR (http://www.nfr.org): Network Flight Recorder es un sniffer comercial para detectar intrusiones en los
sistemas.
*
Logcheck (http://www.psionic.com/abacus/logcheck): es parte del proyecto Abacus de utilidades de
seguridad que ayuda a mostrar los
problemas y violaciones de
seguridad en los
archivos
log del sistema, analizando cada línea y clasificándola según
diferentes niveles de alerta (ignorar, actividad inusual, violación de
seguridad y ataque) para luego enviar los resultados al administrador por e-mail.
*
Perl (http://www.perl.org): Practical Extraction and Report Language es un lenguaje de scripts que corre en cualquier
sistema operativo y que sirve, entre otras múltiples cosas, para crear exploits y explotar las vulnerabilidades de los
sistemas.
*
Ngrep (http://www.packetfactory.net/Projects/ngrep):
herramienta sensible a pcap que permite especificar expresiones
regulares extendidas contra la carga de datos de los paquetes.
Actualmente reconoce TCP, UDP e ICMP sobre ethernet a través de PPP,
SLIP e interfaces nulos.
*
Cheops (http://www.marko.net/cheops): sirve para mapear redes locales o remotas y muestra qué
Sistema Operativo (SO) tienen las máquinas de la red.
*
Vetescan (http://www.self-evident.com): es un scanneador de vulnerabilidades que contiene
programas para comprobar y/o explotar exploits conocidos de redes para
Windows y Unix y corregirlos.
*
Retina (http://www.eeye.com/html/Products/Retina.html):
este programa es un conocido scanneador de vulnerabilidades que es
comercial y que incluye la forma de arreglar todos los agujeros de
seguridad que encuentre. Es para
Windows.
*
Libnet (http://www.packetfactory.net/libnet): conjunto de rutinas para la construcción y guía de una red.
*
Crack (ftp://ftp.cerias.purdue.edu/pub/tools/unix/pwdutils/crack/): este programa es un password cracker.
*
Cerberus Internet Scanner (http://www.cerberus-infosec.co.uk/cis.shtml): CIS es otro scanner de
seguridad destinado a ayudar a los administradores de red de
Windows a detectar y corregir agujeros de
seguridad.
*
Swatch (http://www.stanford.edu/~atkins/swatch): utilidad para monitorizar los mensajes de los
archivos log de Unix mediante el comando syslog lanzando eventos con múltimples métodos de alarma.
*
OpenBSD (http://www.openbsd.org): OpenBSD es una distribución libre de
sistemas Unix multiplataforma basada en 4.4BSD. OpenBSD incluye emulación de binarios para la mayoría de los
programas de los
sistemas SVR4 (Solaris),
Linux, SunOS, HP-UX, etc e incluye también OpenSSH con soporte para SSH1 y SSH2.
*
Nemesis (http://www.packetninja.net/nemesis).
*
LSOF (http://vic.cc.purdue.edu/pub/tools/unix/lsof): herramienta de diágnostico de
sistemas
Unix que lista la información de cualquier archivo que es abierto por
un proceso que se esté ajecutando. Muy útil para detectar troyanos y
sniffers.
*
LIDS (http://www.turbolinux.com.cn/lids): este es un sistema de detección/defensa para
Linux contra intrusiones de root deshabilitando algunas llamadas del sistema al kernel.
*
IPTraf (http://www.mozcom.com/riker/iptraf):
monitor de red que genera multitud de estadísticas como información TCP,
contador UDP, información ICMP y OSPF, estado de los nodos, errores IP,
etc.
*
IPLog (http://ojnk.sourceforge.net): logger del tráfico TCP/IP, UDP e ICMP que detecta scanneos y posibles ataques para
sistemas Unix.
*
Fragrouter (http://www.anzen.com/research/nidsbench): ni idea.
*
QueSO (http://www.apostols.org/projects/queso): utilidad para averiguar qué
Sistema operativo corre en una máquina remota analizando las respuestas TCP. Funciona bajo Unix (
Linux) y algunas de sus pruebas de detección han sido incluidas al famoso programa NMAP.
*
GPG/PGP (http://www.gnupg.org y http://www.pgp.com):
substituto del PGP con licencia GNU desarrollado en Europa que no
utiliza ni el algoritmo RSA ni IDEA y que por ello no tiene ningún tipo
de restricción. PGP o Pretty Good Privacy es el famoso sistema de
encriptación que ayuda a asegurar y codificar la información contra
posibles “escuchas”.
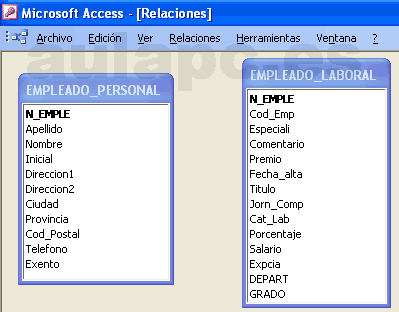
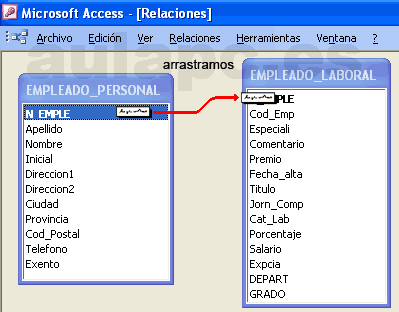
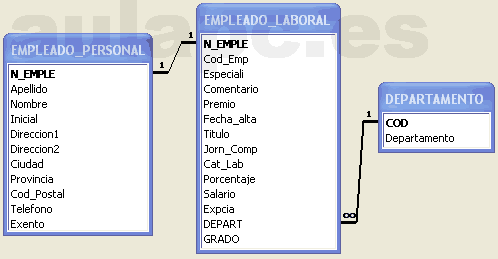
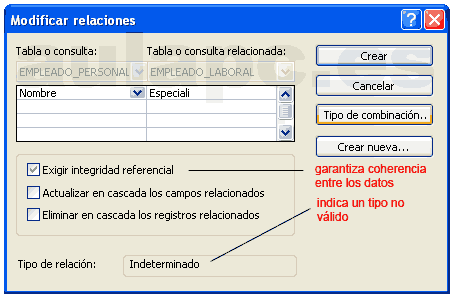
 ) que colocamos encima del campo de destino y
soltamos...
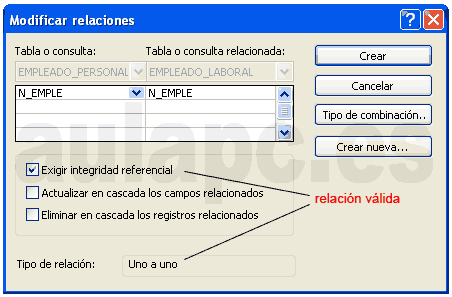
) que colocamos encima del campo de destino y
soltamos...